Wrapping the API into a production container¶
In the previous chapter, we have created an API that can log requests and return responses locally. We need to wrap everything up into a docker container to make it available to the outside world.
First off all, lets see the file structure and recap what is the logic behind each of the file and directory in the project folder.
!tree ML_API_docker -L 2
ML_API_docker
├── alembic
│ ├── env.py
│ ├── __pycache__
│ ├── README
│ ├── script.py.mako
│ └── versions
├── alembic.ini
├── app.py
├── database
│ ├── config.yml
│ ├── database.py
│ ├── __init__.py
│ ├── jwt_tokens.py
│ ├── ML.py
│ ├── __pycache__
│ └── Users.py
├── data_docker
│ └── db
├── docker-compose.yml
├── Dockerfile
├── gunicorn_config.conf
├── __init__.py
├── ml_model
│ ├── input_schema.json
│ └── model.pkl
└── requirements.txt
8 directories, 18 files
The alembic directory manages the migrations and that the changes in the python files get reflected in the database.
The alembic.ini file is the configuration file for the alembic package. It holds the connection string to the database and the location of the migration scripts. In a real life application you should not track this file because it contains the full connection URI.
The app.py file is the main file of the API. It imports all the necesary logic to run and creates the FlaskAPI object which is used in runtime.
The database directory holds all the database models and other associated logic.
The data_docker directory links the data from PSQL in a docker container to the local machine. This way, if restart the container, all the data is saved and we do not need to rerun all the migrations.
The docker-compose.yml file creates the two containers: 1 for the PSQL service and 1 for the API service.
The Dockerfile handles the image creation for the API application.
The gunicorn_config.conf is a configuration file for the supervisor application to serve the API using gunicorn.
The __init__.py file indicates for python that the whole directory is a package. This makes certain imports not break.
The ml_model holds the files necesary for the machine learning model.
Lastly, the requirements.txt file holds the dependencies for the API.
Dockerfile¶
The dockerfile commands will create an image which can be used to spin up the docker container.
!cat ML_API_docker/Dockerfile
# Base image. We will use the Ubuntu base image and populate it
FROM ubuntu:20.04
# Updating all the base packages and installing python and pip
RUN apt-get update && apt-get install -y python3-pip
# Installing supervisor to manage the API processes
RUN apt-get install -y supervisor
# Creating the working directory **inside** the container. All the subsequent commands will be executed in this directory.
WORKDIR /app
# Copying the requirements.txt file to the container. The . means that copy everything to the current WORKDIR (which is /app)
COPY requirements.txt .
# Installing every package in the requirements.txt file
RUN pip3 install -r requirements.txt
# Copying over the app code to the container
COPY app.py .
# Copying the database functionalities
COPY database/ /app/database/
# Copying the ml_model folder to the container
COPY ml_model/ /app/ml_model/
# Copying the configuration for the supervisor process
COPY gunicorn_config.conf /etc/supervisor/conf.d/gunicorn_config.conf
# Running the gunicorn process
CMD ["/usr/bin/supervisord", "-c", "/etc/supervisor/supervisord.conf"]
To build the image use the command:
docker build -t ml-api .
Running the containers¶
The built image is used in the docker-compose.yml file alongside another container for psql:
!cat ML_API_docker/docker-compose.yml
version: '3.1'
services:
psql_db:
image: postgres:14.1
restart: always
environment:
POSTGRES_PASSWORD: password
POSTGRES_USER: user
ports:
- "5444:5432"
volumes:
- ./data_docker/db:/var/lib/postgresql/data
ml_api:
image: ml-api
restart: always
ports:
- "8999:8900"
The container for the ml-api will will link requests from 8999 port on the local machine to port 8900 inside the container.
If the container goes down for some reason, the docker background process will restart it.
To spin up both the containers use the command:
docker-compose up
Be sure to make the necesary migrations if this is the initial run of the containers:
alembic revision -m "Creating migrations" --autogenerate
And apply them:
alembic upgrade head
High level schema¶
To get a better view of what processes get start after the command docker-compose up, lets illustrate the high level schema:
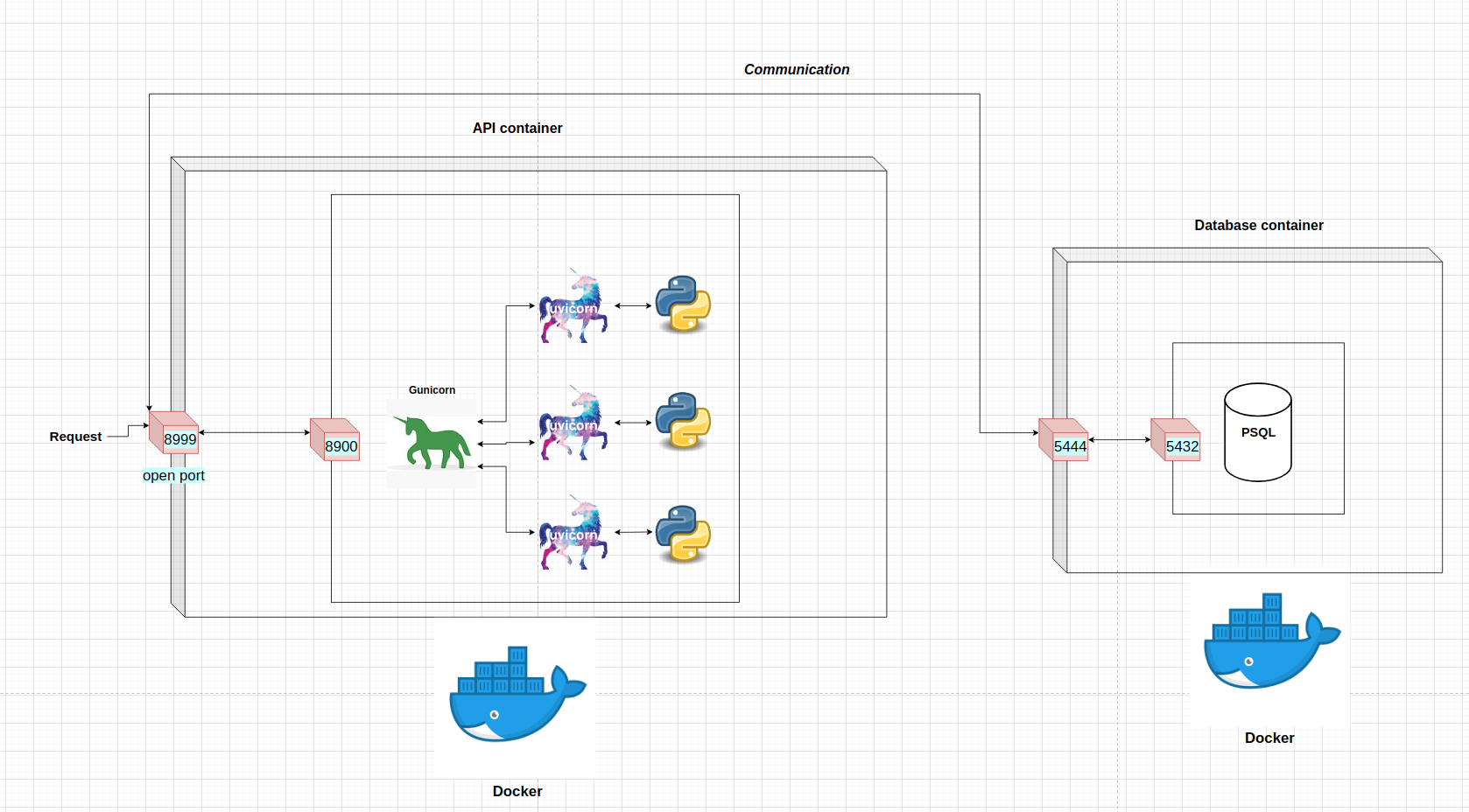
Both of the containers are managed by docker.
The only port where the requests can come in for the machine learning API is through the port 8999. All the requests get redirected to the port 8900 inside the container. From there, gunicorn gives the request to one of the workers.
The container with the PSQL database can be reached via port 5444 on the local machine. The data gets redirected to the port 5432 inside the container.
Using the API from the container¶
All the API calls will be done to the container which is running on the local machine.
Creating a user¶
# Importing the package
import requests
# Defining the URL
url = 'http://localhost:8999'
# Defining the user dict
user_dict = {
"username": "eligijus_bujokas",
"password": "password",
"email": "eligijus@testmail.com"
}
# Sending the post request to the running API
response = requests.post(f"{url}/register-user", json=user_dict)
# Getting the user id
user_id = response.json().get("user_id")
# Printing the response
print(f"Response code: {response.status_code}; Response: {response.json()}")
Response code: 409; Response: {'message': 'User already exists', 'user_id': 1}
Getting the token¶
# Registering the user to docker
response = requests.post(f"{url}/token", json={"username": "eligijus_bujokas", "password": "password"})
# Extracting the token from the response
token = response.json().get("token")
# Printing the response
print(f"Response code: {response.status_code}; JWT token: {token}")
Response code: 200; JWT token: eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE2NDIzNDE1NTIsImlhdCI6MTY0MjMzNzk1Miwic3ViIjoxfQ.peBY_b40wHtsINkvipsk0CEgt-tdv_cLhV7S44hIWto
Getting the predictions¶
# Creating the input dictionary
X = {
'age': 25,
'creatinine_phosphokinase': 1000,
'ejection_fraction': 35,
'platelets': 500000,
'serum_creatinine': 8,
'serum_sodium': 135,
'sex': 1,
'high_blood_pressure': 0
}
# Creating the header with the token
header = {
'Authorization': token
}
# Sending the request
response = requests.post(f"{url}/predict", json=X, headers=header)
# Infering the response
print(f"Response code: {response.status_code}; Response: {response.json()}")
Response code: 200; Response: {'yhat_prob': '0.5124506', 'yhat': '1'}
Conclusion¶
The container accepts requests via the port 8999. If we have a running docker background process on any server, we can spin up this container and use the machine learning model imediatly.
The API itself is served using gunicorn with n workers.
Each worker is an uvicorn async server that will handle the requests.
Gunicorn itself is managed using supervisor.
If the container breaks, then docker daemon will automatically restart it.
Contributions¶
If you enjoyed the book and feel like donating, feel free to do so. The link to do a one time donation is via Stripe.
Additionaly, if you want me to add another chapter or to expand an existing one, please create an issue on Github.