Machine learning API¶
Right now we have 3 database tables:
Users
Requests
Responses
Additionaly, we have created a machine learning model along with the input schema. It is time to create a working API using FastAPI to serve predictions.
Loading the ML model to memory¶
The most efficient way to load an ML model to memory is to save it during the initiation of the FastAPI application. It is a common mistake to read the model file and the schema file everytime a new request comes in and then apply it.
We should import the model objects and create any additional objects at the top of the main app.py script where the API object is beeing created.
The necessary utilities:
!cat ML_API/machine_learning_utils.py
# Pickle object reading
import pickle
# JSON object reading
import json
# OS traversal
import os
# Input dataframe
import pandas as pd
# Array math
import numpy as np
def load_ml_model(model_dir='ml_model'):
"""
Loads the model and the schema from the given path
"""
model, type_dict, feature_list = {}, {}, []
_model_path = os.path.join(model_dir, 'model.pkl')
_input_schema_path = os.path.join(model_dir, 'input_schema.json')
# Default empty input schema
input_schema = {}
# Checking if the files exists and reading them
if os.path.exists(_model_path) and os.path.exists(_input_schema_path):
with open(_model_path, 'rb') as f:
model = pickle.load(f)
with open(_input_schema_path, 'r') as f:
input_schema = json.load(f)
# Extracting the features
features = input_schema.get('input_schema', {})
features = features.get('columns', [])
# Iterating over the list of dictionaries and changing the types.
# numeric -> float
# boolean -> bool
# The resulting dictionary will have a key value of the feature name and the value will be the type
for feature in features:
if feature.get('type') == 'numeric':
feature['type'] = float
elif feature.get('type') == 'boolean':
feature['type'] = bool
type_dict.update({feature.get('name'): feature.get('type')})
# Extracting the correct ordering of the features for the ML input
feature_list = [x.get('name') for x in features]
# Returning the model, type dictionary and the feature order
return model, type_dict, feature_list
def predict(model, feature_dict: dict, X: dict) -> list:
"""
Function that converts the feature_dict into a predictable format for the ml model
Args:
model: the machine learning model
feature_dict: the dictionary of features
X: dictionary with (feature -> feature value) pairs
Returns:
A list of predictions
"""
try:
# Converting the dictionary into a list of lists
feature_list = list(feature_dict.keys())
# Converting the dictionary to a dataframe
X = pd.DataFrame(X, index=[0])
# Ensuring that no columns are missing
if len(feature_list) != X.shape[1]:
for col in X.columns:
if col not in feature_list:
X[col] = np.nan
# Converting the X columns to correct types
for col in X.columns:
if col in feature_list:
try:
X[col] = X[col].astype(feature_dict.get(col))
except:
print(f"Cannot convert {col} to {feature_dict.get(col)}")
# If we cannot convert it, we will set it to null.
return None
# Predicting the output
prediction = model.predict_proba(X[feature_list])[0]
return prediction
except:
return None
The loading of the model occurs right before defining the endpoints:
...
# Creating the application object
app = FastAPI()
# Loading the machine learning objects to memory
ml_model, type_dict, ml_feature_list = load_ml_model()
...
By loading the objects in the following way, the objects are saved in runtime memory and are not loaded from disk everytime a new request comes in. This makes the application much faster.
API usage flowchart¶
A typical flow of the API is the following:
Register a user:
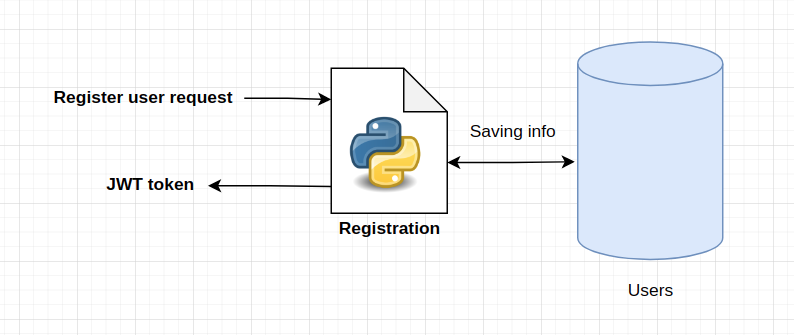
The output of the registration logic is a JWT token which we attach in each of the requests to our API.
Prediction flow:
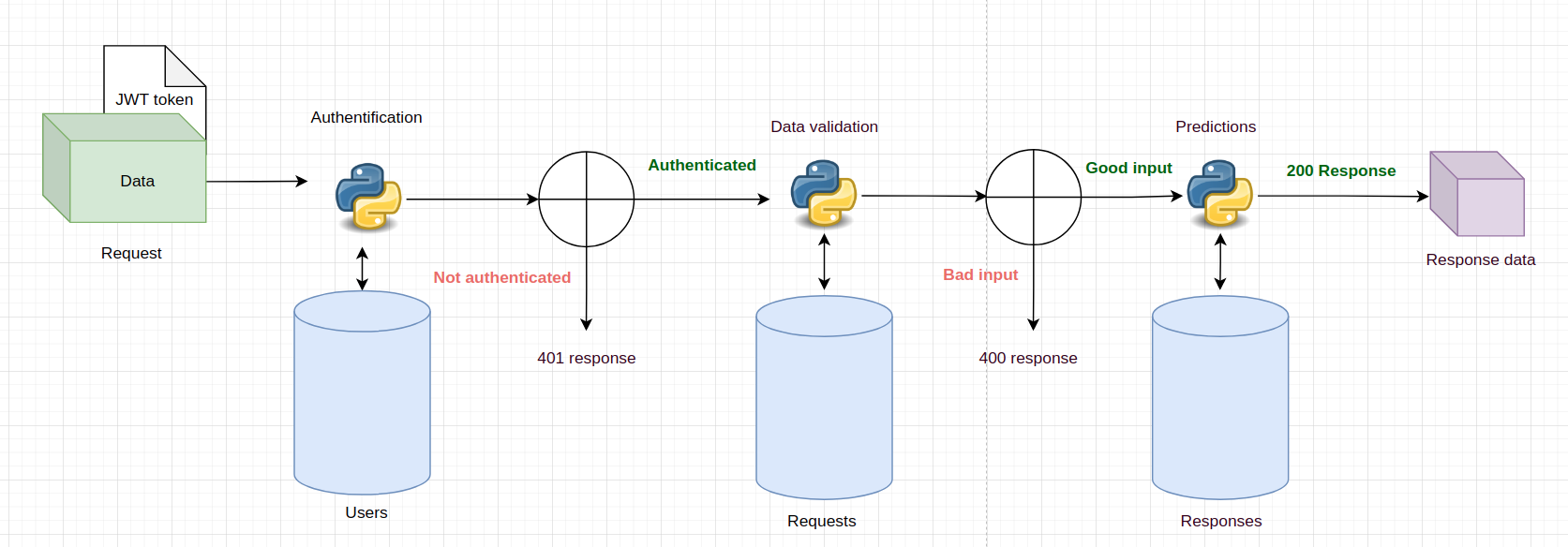
Each request to the API needs to have the JWT token attached to it. Then, along with the token, the data for the API is sent ant the following flow starts:
The user is beeing authenticated.
If the user is authenticated, then the request data is beeing validated for the ML model.
If the data is good, then the prediction is beeing made.
The final response is sent.
Along the way, the information is logged to the Requests and Responses tables.
All the code is available in the app.py script in the ML_API directory so lets try and apply the above flowchart!
API usage¶
# Requests making
import requests
# Defining the constants for the API
url = 'http://localhost:8001'
Creating a user¶
# Defining the user dict
user_dict = {
"username": "eligijus_bujokas",
"password": "password",
"email": "eligijus@testmail.com"
}
# Sending the post request to the running API
response = requests.post(f"{url}/register-user", json=user_dict)
# Getting the user id
user_id = response.json().get("user_id")
# Printing the response
print(f"Response code: {response.status_code}; Response: {response.json()}")
Response code: 409; Response: {'message': 'User already exists', 'user_id': 5}
Getting the token¶
# Querying the API for the token
response = requests.post(f"{url}/token", json=user_dict)
# Extracting the token from the response
token = response.json().get("token")
# Printing the response
print(f"Response code: {response.status_code}; JWT token: {token}")
Response code: 200; JWT token: eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE2NDIzNDc4MDQsImlhdCI6MTY0MjM0NDIwNCwic3ViIjo1fQ.rrQdzFUO9vHEC1nkFBv7cJVvprn6MaXXp1nncNfH2jU
Getting the predictions¶
We need to first recap what was the input used to train the model. The features were:
{
"input_schema": {
"columns": [
{
"name": "age",
"type": "numeric"
},
{
"name": "creatinine_phosphokinase",
"type": "numeric"
},
{
"name": "ejection_fraction",
"type": "numeric"
},
{
"name": "platelets",
"type": "numeric"
},
{
"name": "serum_creatinine",
"type": "numeric"
},
{
"name": "serum_sodium",
"type": "numeric"
},
{
"name": "sex",
"type": "boolean"
},
{
"name": "high_blood_pressure",
"type": "boolean"
}
]
}
}
We will use a POST request to get the probabilities because we want to send the features and their values not as a collection of URL parameters but as a JSON object in the request body.
# Creating the input dictionary
X = {
'age': 25,
'creatinine_phosphokinase': 1000,
'ejection_fraction': 35,
'platelets': 500000,
'serum_creatinine': 8,
'serum_sodium': 135,
'sex': 1,
'high_blood_pressure': 0
}
# Creating the header with the token
header = {
'Authorization': token
}
# Sending the request
response = requests.post(f"{url}/predict", json=X, headers=header)
# Infering the response
print(f"Response code: {response.status_code}; Response: {response.json()}")
Response code: 200; Response: {'yhat_prob': '0.5124506', 'yhat': '1'}
The response dictionary has two keys:
yhat_prob - probability of a death event
yhat - the predicted class; 1 - death_event, 0 - no_death_event
The function predict_ml from the app.py file handles the request and the whole logic is presented here.
The steps are:
Extract the token
Authenticate it
Extract the inputs
Log the request to database
Make the prediction
Log the response to database
Return the response to the user
Inspecting the results¶
All the sufficient information for tracking the API is in the Users, Requests and Responses tables. We can inspect them after our run of requests and responses.
# Importing the connection
import pandas as pd
from ML_API.database import engine
# There maybe some legacy users beside eligjus_bujokas
users = pd.read_sql('select * from users', engine)
print(f"Users in the database:\n{users}")
# Tail of the requests
requests_data = pd.read_sql('select * from requests', engine)
print(f"--\nLast 5 requests:\n{requests_data.tail(5)}")
# Tail of the responses
response_data = pd.read_sql('select * from responses', engine)
print(f"--\nLast 5 responses:\n{response_data.tail(5)}")
Users in the database:
id username password \
0 4 eligijus gAAAAABh0ZTKq-0Es9-BzQd-KJ2R8dNY70vFlj3OY_hsC2...
1 5 eligijus_bujokas gAAAAABh3uroEwCl80d480inMXMCE1TuHjaBYMgmJI3eKL...
2 10 test gAAAAABh4_93mQfHPCQ51tEZ6oLqIZPbADDgIHdNDm2fg9...
email created_datetime \
0 eligijus@testmail.com 2022-01-02 14:04:26.751085
1 eligijus@testmail.com 2022-01-12 16:51:20.534979
2 test@testmail.com 2022-01-16 13:20:23.508369
updated_datetime enabled
0 2022-01-02 14:04:26.751085 True
1 2022-01-12 16:51:20.534979 True
2 2022-01-16 13:20:23.519665 False
--
Last 5 requests:
id user_id input \
20 21 5 {"age": 25, "creatinine_phosphokinase": 1000, ...
21 22 5 {"age": 25, "creatinine_phosphokinase": 1000, ...
22 23 5 {"age": 25, "creatinine_phosphokinase": 1000, ...
23 24 5 {"age": 25, "creatinine_phosphokinase": 1000, ...
24 25 5 {"age": 25, "creatinine_phosphokinase": 1000, ...
created_datetime updated_datetime
20 2022-01-14 20:37:26.669542 2022-01-14 20:37:26.669542
21 2022-01-14 20:42:49.979033 2022-01-14 20:42:49.979033
22 2022-01-16 13:22:03.372336 2022-01-16 13:22:03.372336
23 2022-01-16 13:26:30.148125 2022-01-16 13:26:30.148125
24 2022-01-16 14:43:24.945873 2022-01-16 14:43:24.945873
--
Last 5 responses:
id request_id output \
16 17 21 {"yhat_prob": "0.5124506", "yhat": "1"}
17 18 22 {"yhat_prob": "0.5124506", "yhat": "1"}
18 19 23 {"yhat_prob": "0.5124506", "yhat": "1"}
19 20 24 {"yhat_prob": "0.5124506", "yhat": "1"}
20 21 25 {"yhat_prob": "0.5124506", "yhat": "1"}
created_datetime updated_datetime
16 2022-01-14 20:37:26.694771 2022-01-14 20:37:26.694771
17 2022-01-14 20:42:50.004279 2022-01-14 20:42:50.004279
18 2022-01-16 13:22:03.390882 2022-01-16 13:22:03.390882
19 2022-01-16 13:26:30.155778 2022-01-16 13:26:30.155778
20 2022-01-16 14:43:24.954969 2022-01-16 14:43:24.954969