Databases and Python¶
Alot of modern application can be modeled in the follwowing way:
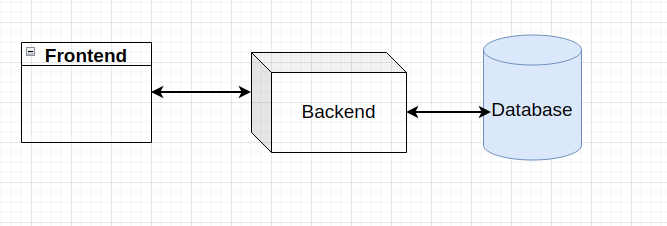
When a user opens an application frontend, either on a desktop or a mobile device, the code on the frontend starts calling the backed via APIs for various data. The backend then queries the database for all the necessary data, does all the computations with it, and sends the data back to the frontend for a nice visualization. One of the modern choices of an application backend is Python and Python has alot of functionalities for connecting and querying databases.
The most common way how does backend interact with frontend and backend is through APIs. Often, the whole API server is just refered to as backend. The backend ussualy does hundreds and thousands calls to the database. But what is a database?
A database is a collection of data organized in a structured way. The data is, in most cases, stored electronicaly on a computer. The way that data is stored on a database is managed by a database management system (DBMS). This means that ‘running a database’ refers to a process which is responsible for storing and retrieving data from a database. As the the database grows in data, so does the size of the database files on computer. To have a good intuitive understanding of a database, think of it as an extension and generalization of a spreadsheet.
Databases and spreadsheets (such as Microsoft Excel) are both convenient ways to store information. The primary differences between the two are:
How the data is stored and manipulated.
Who can access the data.
How much data can be stored.
Spreadsheets were originally designed for one user, and their characteristics reflect that. They’re great for a single user or small number of users who don’t need to do a lot of incredibly complicated data manipulation. Databases, on the other hand, are designed to hold much larger collections of organized information—massive amounts. Databases allow multiple users at the same time to quickly and securely access and query the data using highly complex logic and language.
One of the main advantages of databases is that they can be queried and updated. A database query is a request for data from a given database. The standart way to quety data is to use the Structured Query Language or SQL for short.
Database managment systems (DBMS)¶
There are several very popular DBMS in the industry today. The most popular ones are:
MySQL
PostgreSQL
MongoDB
SQLite
Oracle
Microsoft SQL Server
Every DBMS has its own set of features and a slight variation of the SQL language. In this book, we will be using the open-sourced PostgreSQL DBMS https://www.postgresql.org/about/.
PSQL docker image¶
We will run the PostgreSQL (PSQL for short) database from a docker container. By using docker, we will skip all the headaches of installing various dependencies and setting up the environment. We will just use the official docker image of psql: https://hub.docker.com/_/postgres.
The docker-compose file:
!cat psql-docker/docker-compose.yml
version: '3.1'
services:
db:
image: postgres:14.1
restart: always
environment:
POSTGRES_PASSWORD: password
POSTGRES_USER: user
ports:
- "5432:5432"
volumes:
- ./data/db:/var/lib/postgresql/data
We will use the version 14.1 of PostgreSQL. The container will be listening on port 5432 on the local machine and will transfer data to port 5432 in the container. The 5432 is the default port for PostgreSQL.
Any data added to the container will be stored in the local machine in the directory where the docker-compose file is: ./data/db.
To spin up the PSQL database, run the command (from the directory where the file is):
docker-compose up
The docker ps command should show that the container is running:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e812f56fd0e7 postgres:14.1 "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp psql-docker_db_1
Now we can access the database using any software we like and start putting data in it.
SQLAlchemy¶
One of the most popular libraries to connect and use databases with Python is SQLAlchemy. SQLAlchemy is a Python library that provides a high-level abstraction layer on top of many popular databases. To read the extensive documentation visit https://docs.sqlalchemy.org/en/14/
To connect to most of the databases, we need to know its URI: Uniform Resource Identifier. The URI is a string that contains all the information needed to connect to the database. The URI has the following form:
<dialect+driver>://<username>:<password>@<host>:<port>/<database-name>
For example, to connect to the PostgreSQL database, we need to use the following URI:
postgresql://user:password@localhost:5432/postgres
Make sure that the docker container is running before trying out the bellow code snippet.
# Importing the sqlalchemy library
from sqlalchemy import create_engine
# Query making
import pandas as pd
# Creating the engine
engine = create_engine('postgresql://user:password@localhost:5432/postgres')
# Making a query with pandas and the created engine
pd.read_sql("SELECT * FROM pg_catalog.pg_tables;", engine)
| schemaname | tablename | tableowner | tablespace | hasindexes | hasrules | hastriggers | rowsecurity | |
|---|---|---|---|---|---|---|---|---|
| 0 | pg_catalog | pg_statistic | user | None | True | False | False | False |
| 1 | pg_catalog | pg_type | user | None | True | False | False | False |
| 2 | pg_catalog | pg_foreign_table | user | None | True | False | False | False |
| 3 | pg_catalog | pg_authid | user | pg_global | True | False | False | False |
| 4 | pg_catalog | pg_statistic_ext_data | user | None | True | False | False | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 61 | pg_catalog | pg_largeobject | user | None | True | False | False | False |
| 62 | information_schema | sql_parts | user | None | False | False | False | False |
| 63 | information_schema | sql_implementation_info | user | None | False | False | False | False |
| 64 | information_schema | sql_features | user | None | False | False | False | False |
| 65 | information_schema | sql_sizing | user | None | False | False | False | False |
66 rows × 8 columns
The engine object has all the methods and attributes that you need to interact with the database. As we can see from the query results, PSQL has a lot of default tables that are ready to be used.
Creating a database¶
We can use SQLAlchemy to fully manage database creation and deletion, table managment and data manipulation in a given database management system. The created SQLAlchemy engine object is stored in the variable engine. It has a method called connect() which returns a connection object. The connection object has a method called execute() which executes a given SQL query.
Lets start by creating a database:
# Initiating the connection object from the created engine
conn = engine.connect()
# When initiated, the connection object is in a state of an active transation. We need to commit it in order to make the changes permanent.
conn.execute("commit")
# Giving the database a name
db_name = 'testdb'
# Getting all the database names
databases = pd.read_sql("SELECT datname FROM pg_database;", engine)["datname"].values.tolist()
if db_name in databases:
print(f'Database {db_name} already exists')
else:
print('Database does not exist; Creating it')
# Creating the database
conn.execute("CREATE DATABASE testdb")
conn.commit()
# Listing the databases
print(f"\nDatabases available in PSQL:")
pd.read_sql("SELECT datname FROM pg_database;", engine)["datname"].values.tolist()
Database testdb already exists
Databases available in PSQL:
['postgres', 'db', 'template1', 'template0', 'test_db', 'testdb']
Creating a table¶
When working with databases, there are some key definitions that one must know:
A database schema defines the structure of a database (tables and relationships).
A database model is a class that represents a table in a database (a table in a database).
A model schema defines the structure of a database model (column types and relationships in a table).
A database migration is a set of instructions that tell a database management system how to create or alter a database schema.
When we are creating new tables in SQL, we are first defining a new model schema and then creating a migration to apply the model schema to the database.
To put it simply, we define the collumn names, types and relationships with other tables and then tell psql to create the table. This process is simplified by using SQLAlchemy.
The term ORM is short for Object Relational Mapping. It is a way to map Python classes to tables in a database. SQLAlchemy provides a way to create ORM classes for a given database. We inherit all the methods and attributes from the SQLAlchemy base class Base and then we define the table name and the columns. Internally, the Base class has all the functionalities needed to command the PSQL system to create the table.
# Importing the Table, Metadata and Column objects from the sqlalchemy library
from sqlalchemy import Column
# Importing the declarative_base class from the sqlalchemy library which is used to create
# the base class for all the custom made classes
from sqlalchemy.orm import declarative_base
# Importing the column types
from sqlalchemy import String, Integer, DateTime
When a developer creates new functionalities or changes existing ones, the first place where the changes happen is in the database tables.
For example, lets create a table called users using a class Users.
# Connecting to the newly created testdb database
engine = create_engine(f'postgresql://user:password@localhost:5432/testdb')
# Defining the declarative base class which we will use as a template for all the custom made classes
Base = declarative_base()
class Users(Base):
# The __tablename__ attribute is used to name the table in the database
__tablename__ = 'users'
# Listing out all the columns in the table
id = Column(Integer, primary_key=True)
name = Column(String)
surname = Column(String)
created_at = Column(DateTime)
updated_at = Column(DateTime)
def __init__(self, name, surname, created_at, updated_at):
"""
Constructor to initialize the class.
Every object created is a ROW in the database
The collumn ID will automatically be created as the primary key and will increase by 1 with each new row created.
"""
self.name = name
self.surname = surname
self.created_at = created_at
self.updated_at = updated_at
def get_full_name(self):
"""
Method to get the full name of the user
"""
return f"{self.name} {self.surname}"
def get_create_datetime(self):
"""
Method to get the exact time when the user was created
"""
return self.created_at.strftime("%Y-%m-%d %H:%M:%S")
# Listing the tables available in the database
tables = pd.read_sql("SELECT * FROM pg_catalog.pg_tables;", engine)["tablename"].values.tolist()
if 'users' in tables:
print(f'Table users already exists')
else:
# To create the table in SQLAlchemy we will use the Base.metadata.create_all() method
Base.metadata.create_all(engine)
Table users already exists
The class Users inherits everything from the Base class. That is why SQLAlchemy nows how to deal with it and manage it. To create the object user, we use the class constructor.
# Importing the package for date wrangling
from datetime import datetime
# Creating the user
eligijus = Users('Eligijus', 'Bujokas', datetime.now(), datetime.now())
# Getting the full name
print(f"Full name of user: {eligijus.get_full_name()}")
# Getting the exact time when the user was created
print(f"Time of user creation: {eligijus.get_create_datetime()}")
Full name of user: Eligijus Bujokas
Time of user creation: 2022-01-16 10:20:33
So far, the object eligijus only lives in the computer memory. The database has no record of such user. In order to insert a new row to the table Users, we need to create a new session and then add the user to the session.
Updating tables¶
To transfer objects from computer memory to the database, we can use SQLAlchemy’s session object. The session object has a method called add() which adds an object to the session. The session object has a method called commit() which actually writes the changes to the database.
We can open and close the sessions as many times as we want and in many code places. Altough the best practise is to use the same session object for all the code in a given code block.
# Importing the session object from the sqlalchemy library
from sqlalchemy.orm import sessionmaker
# Creating the session class and "linking it" with our connection
Session = sessionmaker(bind=engine)
# Creating the session objects with the needed methods
session = Session()
# Adding the user eligijus to the session
session.add(eligijus)
# Uploading to database
session.commit()
Under the hood, SQLAlchemy handles all the data type checks and data conversion from Python to PSQL and vice versa. To see our created user in the database, we can use the query() method of the session object (or just plain Pandas).
# Listing all the users in the database (using Pandas)
pd.read_sql("SELECT * FROM users;", engine)
| id | name | surname | created_at | updated_at | |
|---|---|---|---|---|---|
| 0 | 2 | Bligijus | Eujokas | 2021-12-18 18:03:07.252155 | 2021-12-18 18:03:07.252156 |
| 1 | 4 | Bligijus | Eujokas | 2021-12-18 18:24:53.184050 | 2021-12-18 18:24:53.184051 |
| 2 | 5 | Eligijus | Bujokas | 2021-12-18 22:14:30.569273 | 2021-12-18 22:14:30.569274 |
| 3 | 6 | Bligijus | Eujokas | 2021-12-18 22:14:30.594212 | 2021-12-18 22:14:30.594213 |
| 4 | 3 | Eligijus | Kazlauskas | 2021-12-18 18:24:53.153895 | 2021-12-18 22:14:30.611188 |
| 5 | 7 | Eligijus | Bujokas | 2022-01-05 06:44:33.996557 | 2022-01-05 06:44:33.996559 |
| 6 | 8 | Bligijus | Eujokas | 2022-01-05 06:44:34.017676 | 2022-01-05 06:44:34.017677 |
| 7 | 1 | Eligijus | Kazlauskas | 2021-12-18 17:49:52.135190 | 2022-01-05 06:44:34.030981 |
| 8 | 9 | Eligijus | Bujokas | 2022-01-16 10:20:33.741444 | 2022-01-16 10:20:33.741445 |
# Listing all the users in the database (using query())
users = session.query(Users).all()
[(user.id, user.name, user.surname) for user in users]
[(2, 'Bligijus', 'Eujokas'),
(4, 'Bligijus', 'Eujokas'),
(5, 'Eligijus', 'Bujokas'),
(6, 'Bligijus', 'Eujokas'),
(3, 'Eligijus', 'Kazlauskas'),
(7, 'Eligijus', 'Bujokas'),
(8, 'Bligijus', 'Eujokas'),
(1, 'Eligijus', 'Kazlauskas'),
(9, 'Eligijus', 'Bujokas')]
We can create even more users and add them to the database.
# Creating and uploading
bligijus = Users('Bligijus', 'Eujokas', datetime.now(), datetime.now())
session.add(bligijus)
session.commit()
# Listing all the users in the database (using Pandas)
pd.read_sql("SELECT * FROM users;", engine)
| id | name | surname | created_at | updated_at | |
|---|---|---|---|---|---|
| 0 | 2 | Bligijus | Eujokas | 2021-12-18 18:03:07.252155 | 2021-12-18 18:03:07.252156 |
| 1 | 4 | Bligijus | Eujokas | 2021-12-18 18:24:53.184050 | 2021-12-18 18:24:53.184051 |
| 2 | 5 | Eligijus | Bujokas | 2021-12-18 22:14:30.569273 | 2021-12-18 22:14:30.569274 |
| 3 | 6 | Bligijus | Eujokas | 2021-12-18 22:14:30.594212 | 2021-12-18 22:14:30.594213 |
| 4 | 3 | Eligijus | Kazlauskas | 2021-12-18 18:24:53.153895 | 2021-12-18 22:14:30.611188 |
| 5 | 7 | Eligijus | Bujokas | 2022-01-05 06:44:33.996557 | 2022-01-05 06:44:33.996559 |
| 6 | 8 | Bligijus | Eujokas | 2022-01-05 06:44:34.017676 | 2022-01-05 06:44:34.017677 |
| 7 | 1 | Eligijus | Kazlauskas | 2021-12-18 17:49:52.135190 | 2022-01-05 06:44:34.030981 |
| 8 | 9 | Eligijus | Bujokas | 2022-01-16 10:20:33.741444 | 2022-01-16 10:20:33.741445 |
| 9 | 10 | Bligijus | Eujokas | 2022-01-16 10:20:33.764021 | 2022-01-16 10:20:33.764022 |
Querying the database¶
A big feature of SQLAlchemy is the seemless transition between records in database and objects in computer memory. To query the database, we use the query() method of the session object. The query method takes a SQL like query as an argument and returns a list of objects that mathces the query. For example, lets search for all the users with the name eligijus.
# Listing all the users with the name eligijus in the database using session.query()
users = session.query(Users).filter(Users.name == 'Eligijus').all()
# We can then interact with the object in the same way as with any Python method
if len(users) == 0:
print('No users found')
else:
print(f'Found {len(users)} users with the name Eligijus')
print([(user.id, user.name, user.surname) for user in users])
# Extracting the first one
user = users[0]
# Getting the full name
print(f"Full name of user: {user.get_full_name()}")
# Getting the exact time when the user was created
print(f"Time of user creation: {user.get_create_datetime()}")
Found 5 users with the name Eligijus
[(5, 'Eligijus', 'Bujokas'), (3, 'Eligijus', 'Kazlauskas'), (7, 'Eligijus', 'Bujokas'), (1, 'Eligijus', 'Kazlauskas'), (9, 'Eligijus', 'Bujokas')]
Full name of user: Eligijus Bujokas
Time of user creation: 2021-12-18 22:14:30
We can very simply update the user information. Because the user is an object, we can directly change the attributes using the . operator. Lets change the surname of Eligijus to the most typical surname in Lithunia: Kazlauskas.
# Changing the attributes of the user
user.surname = 'Kazlauskas'
# Specifying the exact time when the user was updated
user.updated_at = datetime.now()
# Uploading the changes to the database
session.commit()
What is neat here, is that the session object tracks all the changes that is made in the memory and we do not need to specify which user was changed: the commit() method will automatically update the database. To see the final database, we can list all the rows using pandas.
# Getting all the rows in the database
pd.read_sql("SELECT * FROM users;", engine)
| id | name | surname | created_at | updated_at | |
|---|---|---|---|---|---|
| 0 | 2 | Bligijus | Eujokas | 2021-12-18 18:03:07.252155 | 2021-12-18 18:03:07.252156 |
| 1 | 4 | Bligijus | Eujokas | 2021-12-18 18:24:53.184050 | 2021-12-18 18:24:53.184051 |
| 2 | 6 | Bligijus | Eujokas | 2021-12-18 22:14:30.594212 | 2021-12-18 22:14:30.594213 |
| 3 | 3 | Eligijus | Kazlauskas | 2021-12-18 18:24:53.153895 | 2021-12-18 22:14:30.611188 |
| 4 | 7 | Eligijus | Bujokas | 2022-01-05 06:44:33.996557 | 2022-01-05 06:44:33.996559 |
| 5 | 8 | Bligijus | Eujokas | 2022-01-05 06:44:34.017676 | 2022-01-05 06:44:34.017677 |
| 6 | 1 | Eligijus | Kazlauskas | 2021-12-18 17:49:52.135190 | 2022-01-05 06:44:34.030981 |
| 7 | 9 | Eligijus | Bujokas | 2022-01-16 10:20:33.741444 | 2022-01-16 10:20:33.741445 |
| 8 | 10 | Bligijus | Eujokas | 2022-01-16 10:20:33.764021 | 2022-01-16 10:20:33.764022 |
| 9 | 5 | Eligijus | Kazlauskas | 2021-12-18 22:14:30.569273 | 2022-01-16 10:20:33.777360 |
Closing thoughts¶
A modern API cannot be imagined without a corresponding database that holds all the request and response data. Additionally, an API would not give responses without all the necessary tables in the database. Python is a very flexible tool to create and manage databases. The object orianted programming paradigm is a great way to manage records in a database, because we can view each row in a database table as an object with each collumn values as the object attributes.
Additionally, we can specify complex functionalities in the table classes using Python and use them with each individual row.
In the next chapter, we will connect the API of the root calculation to the database.